
📊 Evaluation & Metrics¶
We defined metrics according to the 4 organelles and (0 to 5) defined deviations of the focus plane to measure the ability to perform the task. We will evaluate each participant on this 4x6 metrics matrix, and the winners will be the ones with the best average over all the metrics.
We will use standard metrics that are used in the field to evaluate the submissions:
-
Mean Absolute Error (MAE) of predicted and ground truth images:
-
Structural Similarity Index Measure (SSIM) of predicted and ground truth images.
-
Pearson Correlation Coefficient (PCC) of predicted and ground truth images.
-
Euclidean & Cosine Distances (ECD) between original and ground truth images (textures metrics).


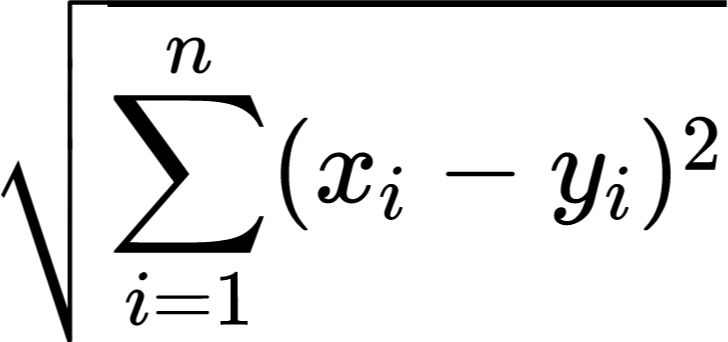
We choose to evaluate the 4 organelles as follows:¶

NB : All cases are not always filled.
ℹ️ As some test images do not contain all the organelles, the metrics will only be calculated if the ground truth image exists, but it is important to predict the 4 output images. ℹ️
💡 Why these metrics ?¶
We chose the MAE as it is less sensible to aberrations than the Mean Square Error (for which the square term enhances error from high intensity signal). PCC is frequently used in the state-of-the art methods and is linked to pixel intensity, which makes sense here for fluorescence images with black background.
The Structural Similarity Index (SSIM) stands out as a metric closely aligned with human vision, factoring in luminance, contrast, and structure. Notably, it is more efficient (than FSIM e.g.) when applied to greyscale images compared to RGB images.SSIM makes sense too as both PCC and MAE, can also be good if the image is very blurred.
PCC has, with SSIM, only an overall similarity: everything is equally important. Therefore, PCC does not take into account variations in structure or texture.
Then, we will evaluate texture features that are usually used for traditional cellular phenotyping.
As there will be no manual annotation, we can only calculate them at the image level, but they will still provide us with a useful additional metric in phenotypic space.
Resulting from this, we choose two additional metrics: the Euclidean and the cosine distance between original and ground truth images.
We choose to use only SSIM and PCC for actin and tubulin evaluation because, as they are not visible to the naked eye on transmitted light images, we risk having a lot of "fuzzy" and therefore not being really sure of the meaning of texture metrics and MAE (even if it's better than MSE).
We have defined these different evaluations to best suit the organelles chosen. Even if we evaluate organelles individually according to their offset from the best focal plane, our objective remains to identify the best algorithm in terms of generalization and adaptability to variability.
🏆 Ranking¶
We will provide both an overall ranking by averaging these scores
described and individual rankings.
Anyone can take part in the challenge. Participants will be displayed in
order of scores, and winners will be determined by the highest overall
average on all individuals ranckings.
Scores will evaluate all participants, regardless of code type and model weight and availability, so as not to limit participation by companies even if they do not wish to distribute their code for intellectual property or commercial reasons.
💎 Bonuses¶
In addition, participants can earn bonus points for aspects such as:
- code Documentation
- code Reusability
- code Accessibility
- and code quality : Codacy
Of course, the bonuses will have no impact on the final ranking, but the methods with the most bonuses will have their place and will be described in the article.
🔓 Evaluation software accessibility¶
All metrics used for the evaluation will be open-source and
accessible.
However, the evaluation software will run automatically on
Grand-Challenge.org on the ground truth images for the test phases.
There are no links yet, but there will be soon.
📈 Evaluation¶
You can access the evaluation code here : https://seafile.lirmm.fr/f/8a17128c73e7493cba47/